Oliver Messner
28.12.2013Client code ignores REPOSITORY implementations; developers do not
Our team is working on an application for one of our clients, a service provider for container logistics, shipping cargo between seaports, terminals and other loading sites. The business domain also includes the calculation of shipping prices subjected to the agreements met between the shipping company and its customers. We recently implemented the concept of so called offers into the application, whereas each offer contains multiple terminal-specific prices. One or more offers may be assigned to a customer (see diagram below, capturing these domain concepts).
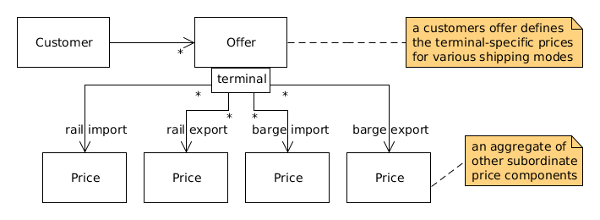
Our technology stack encompasses Spring Framework and JPA as the persistence technology. All the applications data is stored in a relational database.
@Entity
public class Offer {
@ManyToMany(fetch = FetchType.EAGER)
private Map< Long, Price> importBargePrices;
@ManyToMany(fetch = FetchType.EAGER)
private Map< Long, Price> exportBargePrices;
@ManyToMany(fetch = FetchType.EAGER)
private Map< Long, Price> importRailPrices;
@ManyToMany(fetch = FetchType.EAGER)
private Map< Long, Price> exportRailPrices;
...
}
Note the collection-valued associations between offer and price: in the current implementation these have been configured to be eagerly fetched. Setting the fetch type to eager loading forces the JPA provider to instantly fetch these entity attributes from the database when an offer is read.
Beyond JPA we also use Spring Data. So, there’s a repository representing a collection of offers and encapsulating the internal details of database access:
public interface OfferRepository extends
JpaRepository< Offer, Long> {
Offer findByLabel(String label);
}
When things went wrong
Before deploying our application to production, we did some exploratory testing in a production-like environment. During testing, we realized that the application ran out of memory when doing one of the the following operations:
- loading an offer from the database (in order to display its details)
- assigning an offer to a customer
These two use cases have been tested constantly by our acceptance tests, every time the Continuous Integration server finnished building and deploying the application into a test server. Nevertheless, both use cases now turn out to be broken in a production-like environment. One obvious difference between the environment for CI acceptance testing and the production-like environment is the amount of data stored in the database.
Java Virtual Machine monitoring and profiling
with jvisualvm revealed huge memory
consumption when reconstituting a single stored offer entity using the repository method findOne. OfferRepository
extends JpaRepository and therefore provides the aforementioned method;
Spring Datas SimpleJpaRepository implements this method to simply call JPA EntityManagers find method.
@Override
public T findOne(ID id) {
...
Class< T> domainType = getDomainClass();
return type == null ? em.find(domainType, id)
: em.find(domainType, id, type);
}
Analyzing the SQL that gets constructed and executed by the JPA provider discloses a relatively big number of outer joins in the generated select statement; this is not an issue with Spring Data.
“Spring Data JPA itself does not control the interaction with the database directly. All it does is interacting with the EntityManager, so effectively all behavioral effects are defined by JPA and
the underlying OR-mapper.”
Oliver Gierke, Spring Data Project
Introducing the finder method findById into OfferRepository and replacing calls to findOne by calls to findById
had an effect on the generated SQL: instead of one select statement with more than twenty outer joins, we now have
multiple select statements each having three outer joins at most.
public interface OfferRepository extends
JpaRepository< Offer, Long> {
Offer findById(Long id);
Offer findByLabel(String label);
}
In both cases, because the offers collection-valued associations are configured to be eagerly loaded, price data is
implicitly fetched from the database when an offer is initially read. And in case of using findOne, the generated SQL
statement causes the application to crash with an OutOfMemoryError.
But just replacing any call of findOne falls too short. Look at the following code that assigns the specified offer to
a customer:
Offer offer = offerRepository.findById(offerId);
Customer customer = customerRepository.findById(customerId);
customer.addOffer(offer);
customerRepository.save(customer);
First both, the offer and the customer (each specified by Id) are queried from the database. Then, the offer is assigned
to the customer and finally the customer gets updated. A programmer not aware of JPA and Spring Data internals might
overlook that save, which is actually provided by Spring Data, invokes the JPA EntityManagers merge method and he
might not know the details of the JPA concepts of detachment, merging and transaction-scoped persistence contexts.
Now, assume that retrieving the offer and customer and eventually updating the customer are executed not within the same transaction. This means that the offer entity is no longer in managed state when the JPA merge operation does its work. JPA persistence contexts are tied to the lifecycle of a transaction which implies that the JPA provider again reads the offer from database, instantly fetching all of its collection-valued associations, which in our case causes the application to run out of memory (again, there are lots of outer joins in the select statement sent to the database).
Ensuring that reading offers and updating the customer are handled in the same transaction fixes the memory issue, but the better approach would have been to avoid eager loading at all. This not only decreases the impact on memory but also reduces the amount of SQL and speeds up the queries and object loading. These are the reasons that JPA defaults to lazy loading (aka deferred loading, on-demand fetching) for collection-valued associations; but keep in mind that lazy loading is just a hint to the JPA provider, i.e. behaviour will depend on its implementation.
Conclusion
Deepen the knowledge of the technologies you are using
Care about the internal details of the persistence technology. Generally speaking, decoupling clients from repository implementation and the underlying technology is great, but this does not relieve the developers from the need to understand the consequences of using encapsulated behaviour, including its performance and resource-related implications.
In other words:
“Client code ignores REPOSITORY implementations; developers do not”
Eric Evans, Domain-Driven Design
Measure, don’t guess
Testing the application should not only be done on a regular basis and in an automated fashion, but equally important, performance measuring and memory monitoring in production-like environments is essential and must not be ignored. In an iterative development process, these tests should be done in each iteration.